Search
Search
App Types
Discover Amazing AI Applications
Explore our collection of powerful AI applications
Featured Applications
Discover our most popular and recommended AI tools

Generate a smooth, high-quality video starting from a single image. The model adds natural motion, lighting changes, and scene dynamics while keeping the original look and style of the image. Perfect for turning still photos into cinematic shots, dynamic loops, or creative motion sequences.

Minimax Voice Cloning generates realistic speech that mimics a specific voice from an audio sample. It reproduces tone, pacing, and emotion with high accuracy, allowing natural, human-like voice outputs for dialogue, narration, or character performances.

Sora 2 supports generating video clips using an input image and a text prompt together. The uploaded image acts as a visual reference. The prompt guides the action, setting, style, and motion.

Sora 2 is a general-purpose video and audio generation model that turns text prompts into short, realistic video clips with synchronized sound. It builds on the original Sora model from early 2024, but with major upgrades in physical accuracy and controllability.

Bring your static references to life with high-quality AI-generated videos. Vidu Q1 transforms a single reference image or concept into a dynamic, realistic video clip that preserves style, details, and motion consistency. Perfect for creators, marketers, and storytellers, this tool turns inspiration into cinematic animations in just a few clicks.

Go viral with your photos. Viral Image Effects turns everyday shots into trending AI creations — fast, fun, and effortless.

Whether you're working on memes, videos, games, or AI agents, Chatterbox brings your content to life. Use the first tts from resemble ai.

Vidu Template to Video lets you create different effects by applying motion templates to your images.
All Applications(46 apps)

Go viral with your videos. Viral Video Effects turns everyday shots into trending AI creations — fast, fun, and effortless.

Nano Banana 2 is an AI-powered image editing model, that lets you generate new visuals or transform existing photos with simple prompts. It focuses on high-quality outputs, fast generation, and easy editing—like changing styles, adjusting details, or recreating full scenes. It’s built for quick, clean, creative image work without needing pro design skills.

Nano Banana 2 is a compact but insanely powerful AI engine built for creators, developers, and anyone who wants big performance without the bloat. It delivers lightning-speed processing, crisp outputs, and next-level efficiency. Whether you're generating media, analyzing data, or automating workflows, Nano Banana 2 keeps everything smooth, stable, and stupidly fast.
Generate a smooth, high-quality video starting from a single image. The model adds natural motion, lighting changes, and scene dynamics while keeping the original look and style of the image. Perfect for turning still photos into cinematic shots, dynamic loops, or creative motion sequences.

A premium, high-fidelity avatar video generator that brings humans, animals, cartoons, and fully stylized characters to life. Powered by advanced Kling video tech, this endpoint delivers ultra-realistic motion, expressive facial dynamics, and crisp visuals—perfect for creators, apps, and automated content pipelines that need avatar videos that actually look alive.

Minimax Voice Cloning generates realistic speech that mimics a specific voice from an audio sample. It reproduces tone, pacing, and emotion with high accuracy, allowing natural, human-like voice outputs for dialogue, narration, or character performances.

A simple AI tool that helps you write original lyrics and creative stories. Just enter your idea or mood, and it turns your words into a complete song or story in seconds. Perfect for musicians, writers, and anyone who wants to create with ease.

WAN 2.5 Text-to-Image turns written prompts into detailed, high-quality visuals. The model interprets natural language with strong understanding of composition, lighting, and realism, giving you creative control over every generated image.

WAN 2.5 Text-to-Video generates dynamic video clips directly from text prompts. It captures motion, atmosphere, and cinematic tone with remarkable precision — delivering smooth, realistic sequences from pure imagination.

WAN 2.5 Image-to-Video converts a single image into smooth, cinematic video clips. With realistic motion dynamics and temporal consistency, it brings still visuals to life — perfect for storytelling, marketing, and creative animation.

WAN 2.5 Image-to-Image transforms existing images into new, visually coherent variations while preserving core structure and style. It’s ideal for re-styling, upscaling, or creatively re-imagining your original input — powered by WAN’s advanced diffusion pipeline for high-fidelity results.
Sora 2 supports generating video clips using an input image and a text prompt together. The uploaded image acts as a visual reference. The prompt guides the action, setting, style, and motion.
Sora 2 is a general-purpose video and audio generation model that turns text prompts into short, realistic video clips with synchronized sound. It builds on the original Sora model from early 2024, but with major upgrades in physical accuracy and controllability.
Bring your static references to life with high-quality AI-generated videos. Vidu Q1 transforms a single reference image or concept into a dynamic, realistic video clip that preserves style, details, and motion consistency. Perfect for creators, marketers, and storytellers, this tool turns inspiration into cinematic animations in just a few clicks.

Kling 2.5 Turbo Pro: Premium text-to-video generation offering unmatched motion smoothness, cinematic-quality visuals, and outstanding prompt accuracy.

Seedream 4.0, ByteDance’s next-generation image creation model, brings together image generation and editing within a single, unified framework.
Go viral with your photos. Viral Image Effects turns everyday shots into trending AI creations — fast, fun, and effortless.

Upload a shopping receipt image or text, and the AI will automatically extract key details such as store name, date, purchased items, quantities, and prices. This makes it easy to digitize receipts, track expenses, or organize your shopping history.

Generate sound effects using ElevenLabs advanced sound effects model.
Whether you're working on memes, videos, games, or AI agents, Chatterbox brings your content to life. Use the first tts from resemble ai.

Google's state-of-the-art image generation and editing model

Stable Diffusion 3.5 Large is a Multimodal Diffusion Transformer (MMDiT) text-to-image model that features improved performance in image quality, typography, complex prompt understanding, and resource-efficiency.

Google's state-of-the-art image generation and editing model

Orpheus TTS is a state-of-the-art, Llama-based Speech-LLM designed for high-quality, empathetic text-to-speech generation. This model has been finetuned to deliver human-level speech synthesis, achieving exceptional clarity.

Veo 3 by Google, the most advanced AI video generation model in the world. With sound on!

Create scenes with one or two people using just selfies and text prompt (without LoRAs)

Generate video clips more accurately with respect to natural language descriptions and using camera movement instructions for shot control.


Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation

Leverage the rapid processing capabilities of AI models to enable accurate and efficient real-time speech-to-text transcription.
Vidu Template to Video lets you create different effects by applying motion templates to your images.

Remove all text and writing from images while preserving the background and natural appearance.
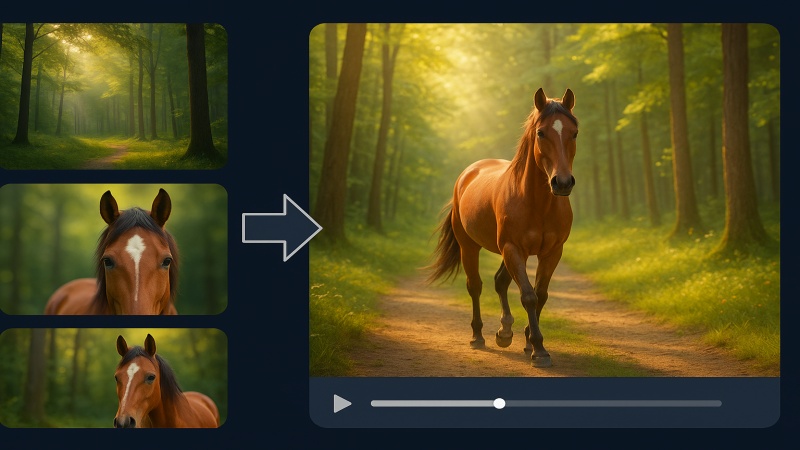
Create seamless transition between images using PixVerse v4.5

A model for high quality and smooth background removal for videos.

Generate video prompts using a variety of techniques including camera direction, style, pacing, special effects and more.

CassetteAI’s model generates a 30-second sample in under 2 seconds and a full 3-minute track in under 10 seconds. At 44.1 kHz stereo audio, expect a level of professional consistency with no breaks, no squeaks, and no random interruptions.
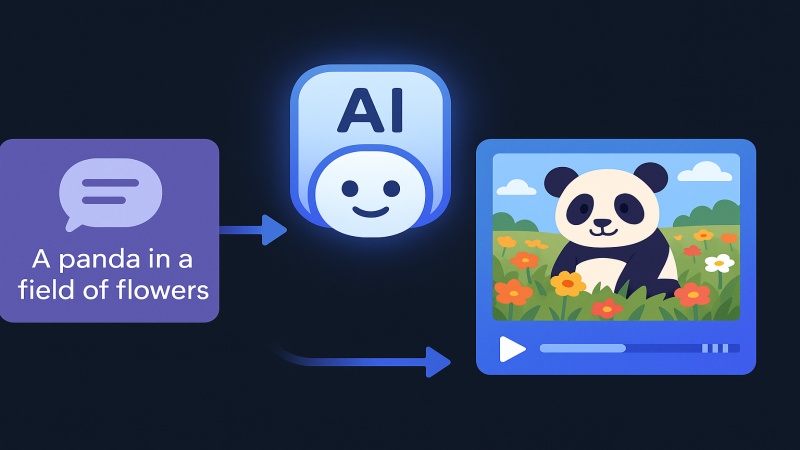
MAGI-1 is a video generation model with exceptional understanding of physical interactions and cinematic prompts

Accelerated image generation with Ideogram V2 Turbo. Create high-quality visuals, posters, and logos with enhanced speed while maintaining Ideogram's signature quality.

Moondream2 is a highly efficient open-source vision language model that combines powerful image understanding capabilities with a remarkably small footprint.


InstantCharacter creates high-quality, consistent characters from text prompts, supporting diverse poses, styles, and appearances with strong identity control.

Place any product in any scenery with just a prompt or reference image while maintaining high integrity of the product. Trained exclusively on licensed data for safe and risk-free commercial use and optimized for eCommerce.

Generate music from text prompts using the MiniMax model, which leverages advanced AI techniques to create high-quality, diverse musical compositions.
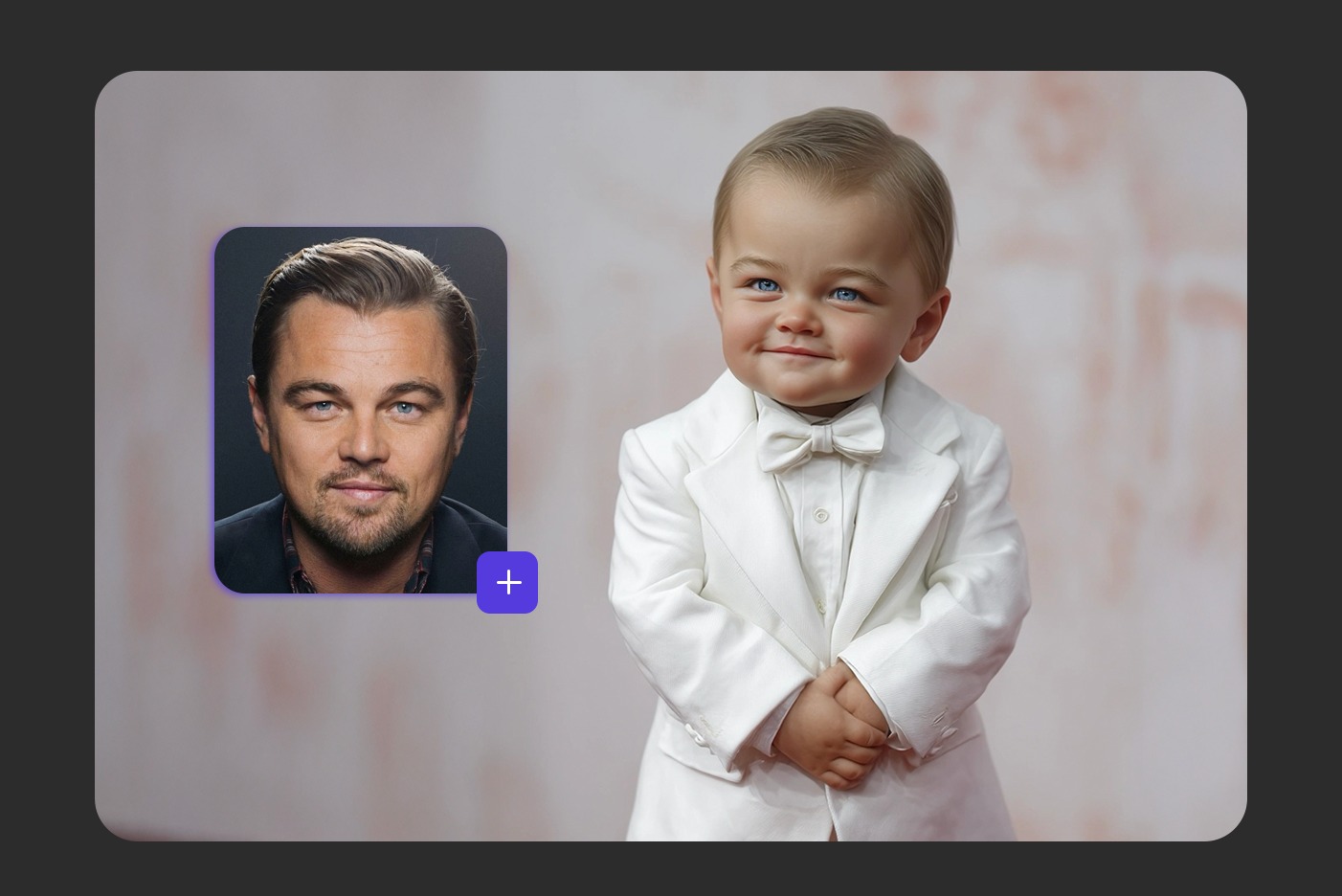
Transform any person into their baby version, while preserving the original pose and expression with childlike features.

Flux.1 Kontext Pro is an advanced AI tool that lets you edit or create images simply by describing what you want — no design skills needed. Whether you're changing text on a sign, adjusting colors, or placing a character in a new scene, you can do it all just by typing natural language instructions.